Read in this order
| # | Explainer | What it answers | One line |
|---|---|---|---|
| 1 | Laitent mission | What is this company, and what does it do? | We turn the know-how locked in experts' heads into instructions AI agents can run. |
| 2 | Uber Eats SynthEnv | How do we prove an agent can do a real job? | We build it a scoreable practice arena, and we explain when that is worth doing vs just using a public site. The earlier (about a month ago) clean example. |
| 3 | The iteration machine | How does the system get good by itself? | An automatic write-score-fix loop that drives rough agent instructions to the edge of trustworthy, honestly. The main event -- the last 48 hours of work. |
What Laitent Is
We map every automation opportunity in a business and tell you when each one becomes ready -- now, or in 6, 12, or 18 months.
For: Rashid | Status: first-pass draft | Date: Tue 23 Jun 2026
"The map is not the territory, but it is the best map money can buy."
In one sentence
Laitent maps all the automation work waiting inside a business and tells you when each piece becomes automatable. It does this by passively watching real work, then letting AI agents try to do that same work and measuring how well they cope.
(The company is also called aTTa, or DKE, short for Domain Knowledge Extraction. Same thing.)
The key shift: the product is the map, not the robots
This is the part to get right. Laitent does not primarily hand you finished automations. The product is the map, the roadmap, and the institutional confidence to scale automation across the whole business.
Here is why that is the valuable part. Today every company knows it should "use AI agents", but nobody can tell them, with evidence:
- What to automate (which of our hundreds of tasks).
- In what order (what pays off first, what to wait on).
- When each task will actually be ready.
That knowledge is the scarce, expensive thing. Once you know it, building the automations is the easy, downstream part. Laitent sells the knowing.
THE OLD WAY THE LAITENT WAY
"Here is one robot "Here is a map of ALL your
we built for you." automatable work, in priority
order, with dates for each."
| |
v v
You got one task done. You can fund and sequence a
You still do not know whole automation programme
what to do next. with confidence. The robots
come after -- the right ones,
in the right order.
How it works (a loop, run at the scale of a whole business)
Laitent runs the same loop over an automation guild -- the group of workers whose tasks we are assessing.
- Passively study the guild. We record real work using Screenpipe (a screen-plus-audio recorder). It is non-intrusive; people just do their jobs.
- Let agents try. For each task, we automatically run AI agents that attempt the same task, again and again, improving each round. (This is the "iteration machine"; see
03-iteration-machine-explainer.md.) - Measure the success rate. How often the agent succeeds at a task is our honest proxy for "how automatable is this task right now?"
- Project over time. Today's score places a task on the map. As AI agents get more capable, we re-measure and extrapolate, giving a now / +6 / +12 / +18 month view of when each task crosses into "automatable". The future horizons are a forecast, not a promise -- which is exactly why it is the best map money can buy, not a crystal ball.
- Output the map and roadmap. A business-wide picture of what to automate, in what order, and when, plus the confidence to fund the rollout. It is a scaffold for scaling automation massively.
WATCH real work --> AGENTS attempt it --> MEASURE success rate
^ |
| v
+------------ PROJECT forward in time <------+
(now / +6 / +12 / +18 months)
|
v
THE MAP + ROADMAP (the product)
The centerpiece: the automation map
This is what the customer is really buying. Each row is a task or role in the guild. Each column is a point in time. A cell shows whether that task has crossed the line into "an agent can reliably do this".
AUTOMATION MAP (illustrative)
Task / role Now +6mo +12mo +18mo
--------------------- ---- ---- ---- ----
Menu data entry # # # #
Invoice matching . # # #
Customer email triage . . # #
Refund decisions . . . #
Contract review . . . .
Legend: # = automatable (agent reliably succeeds)
. = not yet (still needs a person)
Read it left to right and you get a rollout plan: automate menu data entry today, line up invoice matching for the next two quarters, and plan ahead for the rest. The earliest "#" in each row is the moment that task is ready to fund.
Why you can trust the map
A map is only worth funding if the scores are honest. AI models are confidently wrong a lot, and a naive scorer would inflate the map, marking tasks "ready" when they are not.
Laitent resists this in two ways:
- Agents actually attempt the tasks. We do not ask a model for its opinion on whether a task is automatable. We make agents try, and we measure what really happens. That is adversarial execution.
- A Blinded Counsel grades the result. A Blinded Counsel (BC) is a panel of independent AI judges that score the work separately. When they disagree, that disagreement is the signal: it flags a hard, low-confidence cell that needs a human to confirm.
ONE MODEL (inflates the map) BLINDED COUNSEL (honest score)
+-------------+ +---------+ +---------+ +---------+
| "Sure, an | | Judge 1 | | Judge 2 | | Judge 3 |
| agent can | +----+----+ +----+----+ +----+----+
| do that." | | | |
+-------------+ v v v
| +----------------------------------+
v | Agree --> trust the cell |
sounds right, | Disagree --> hard bit: mark it |
may be wrong, | low-confidence, ask a human |
nobody warns you. +----------------------------------+
We use 3, 5, or 7 judges depending on how much rigor a cell needs. The company motto is strong-beliefs-weakly-held: treat every prior score as a guess and re-verify it.
Where "watch a human, write it down" fits
You may hear about Skill-SOPs. A Skill-SOP is a Standard Operating Procedure (reliable step-by-step instructions for a task) written so an AI agent can run it. To test whether an agent can do a task, we often first capture the human's method as a Skill-SOP for the agent to attempt.
This matters, but it is one part of the machine, not the headline. The Skill-SOP is an input and a byproduct. The map is the product.
Why this matters now
Every business is being told to automate, but they are guessing in the dark about what is ready and what is hype. Laitent replaces the guess with an honest, measured map and a dated roadmap -- so leaders can fund the right automation, in the right order, at the right time.
The Uber Eats Example: A Practice Arena That Measures an Agent
How we put a number on whether an AI agent can do one real job.
For: Rashid | Status: first-pass draft | Date: Tue 23 Jun 2026
1. What this example is, and why it matters
First, the big picture. Our product is not a pile of automations. It is a map of the whole business showing which jobs an AI agent can do, and WHEN: now, in 6 months, in 12, in 18. The number we put in each box on that map is the agent success rate: how often an agent does that job correctly.
To get that number, an agent has to ATTEMPT the job and be SCORED against a known-correct answer. For jobs you can practise on a public website, you score there. For jobs with no public place to do that, we build a practice arena. This explainer is one such case.
A few terms, defined once:
- Laitent (also called aTTa or DKE): our company. The one-liner is "task mining for the agent era". We study the small jobs people do on computers so AI agents can learn to do them.
- SOP: a Standard Operating Procedure. Plain English: a step-by-step recipe for a task. A Skill-SOP is the version written for an AI agent.
- SynthEnv (synthetic environment, also "task sandpit"): a practice arena we BUILD from scratch, filled with fixed known-correct data, where an agent can attempt a task and be marked against that fixed answer key.
- Ground truth: the known-correct answer we score against.
In one line: a SynthEnv is the measuring instrument we use to turn one job into one score on the map.
2. The task: quality-control on a "menu extractor"
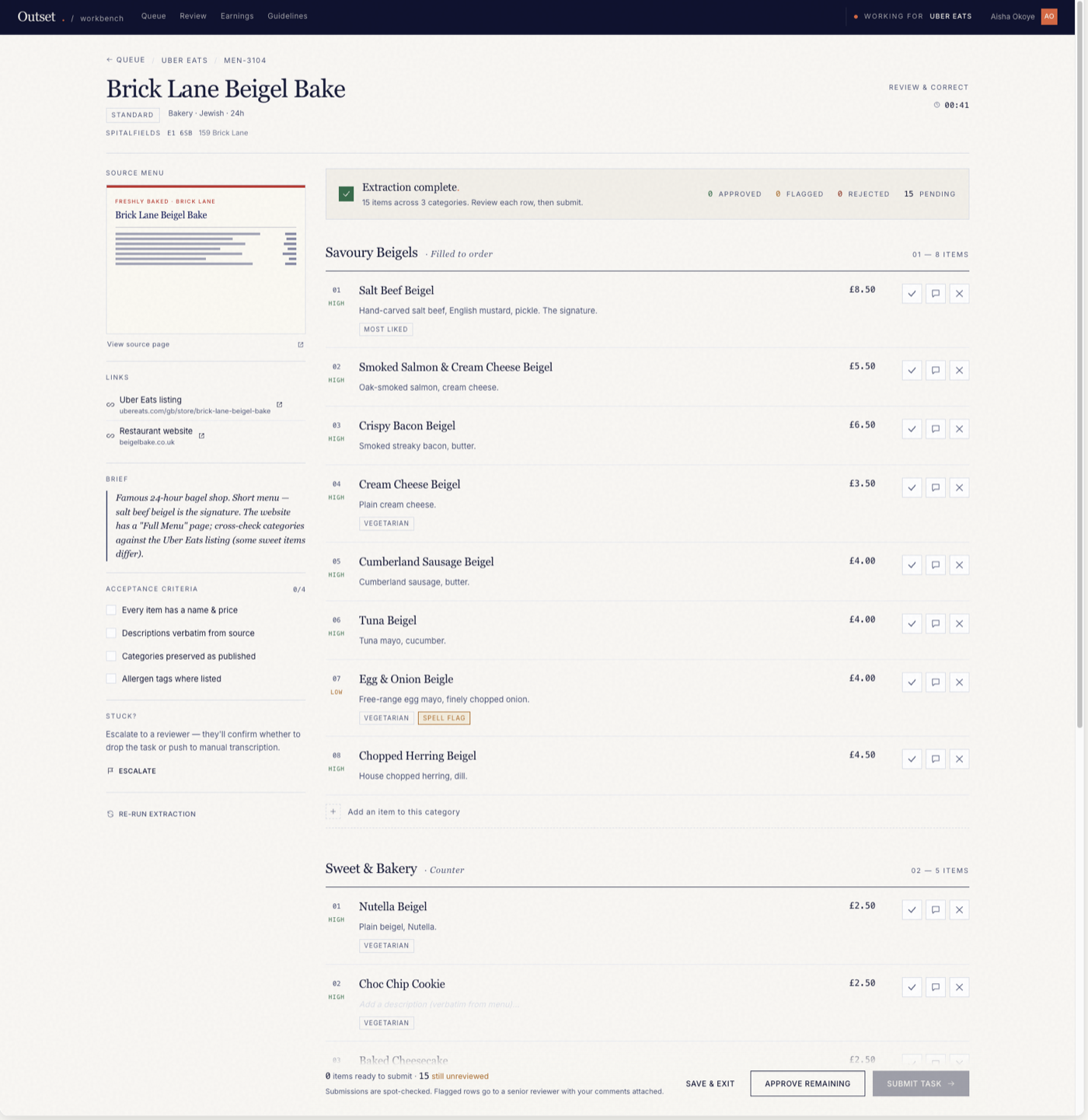
Set the scene. A "menu extractor" is an AI model that reads a restaurant's menu (from its Uber Eats page or its own website) and tries to pull out clean, structured data: each item, its category, its price, its description, and any allergen tags.
Models make mistakes. So a human worker checks the model's work. That worker's job is quality control: go down the list row by row, compare each extracted row against the real menu, and decide APPROVE, FLAG, or REJECT. Genuinely unclear rows get escalated to a senior reviewer.
Here is the loop:
+---------------------+
| SOURCE MENU | the real restaurant menu
| (ground truth) |
+----------+----------+
|
v
+---------------------+
| MENU EXTRACTOR | the AI model reads the menu
| (the AI model) |
+----------+----------+
|
v
+---------------------+
| ROWS TO REVIEW | one row per menu item it found
+----------+----------+
|
v
+---------------------+
| HUMAN QC | check each row vs source, then:
| |
| approve ---------+--> good row, keep it
| flag ---------+--> looks off, mark it
| reject ---------+--> wrong, throw it out
| escalate ---------+--> too unclear, send to senior
+----------+----------+
|
v
+---------------------+
| SUBMIT | finished, checked menu
+---------------------+
Why we picked this one: it is clean. It is mostly a single, repeating task, which makes it a good first teaching case.
Honest caveat: most real work sessions are messier than this. People jump between several different jobs in one sitting. Chopping a screen recording into clean single-task chunks is the genuinely hard part of what we do. The Uber Eats case is the tidy exemplar, chosen on purpose.
3. What you would see (media goes here later)
We have a screenshot of the practice screen and, later, a video of a human doing the work. Those are for a richer explainer down the line. For now, here are labelled placeholders showing where they will sit.
+------------------------------------------+ | [ VIDEO GOES HERE ] ( > play ) | | | | A human doing the QC task end to end, | | row by row, for the multi-modal version.| | | | file: [PLACEHOLDER: video not yet | | recorded / not yet in assets folder] | +------------------------------------------+
The live, clickable practice screen and its source menu live here:
reporting/assets/synthenv-uber-eats-menu-qa.app.html reporting/assets/source-menu-brick-lane-beigel-bake.pdf
4. What a SynthEnv is, and why we built one
There was no public website where you could practise "QA a menu extractor's output" against a fixed answer key. So we BUILT one from scratch: a clean-room copy of an Uber-Eats-style merchant menu-review screen, loaded with fixed data.
The fixed data is a real menu: Brick Lane Beigel Bake. It has 18 menu items across 5 categories (for example "Savoury Beigels" and "Sweet & Bakery"; a sample item is "Salt Beef Beigel, GBP 6.50").
The screen shows the agent (or the human) everything needed to do the job:
- the SOURCE menu (the ground truth to check against),
- the extractor's OUTPUT rows to review,
- the ACCEPTANCE CRITERIA (the marking rubric): every item has a name and a price; descriptions copied word for word from the source; categories kept as published; allergen tags where they are listed,
- the WHY / tacit notes (the unwritten know-how), for example: "the salt beef beigel is the signature item; the website has a separate 'Half Menu' page; cross-check categories against the Uber Eats listing because some items differ between the two",
- the ACTIONS: approve, flag, reject, escalate, re-run extraction, submit.
Because the answer key is fixed, the agent can ATTEMPT the task and then be SCORED against it. That is how we prove the agent can do the job correctly, not just that it looked busy.
5. What actually gets measured here
The whole point of the arena is the score. To make scoring honest, we plant known mistakes (we call them seeded defects) in the rows the agent reviews, for example a wrong price or a description that does not match the source. Then we ask two questions:
- Did the agent catch the planted mistakes? This is recall: of all the real defects, what fraction did it find? Recall 1.0 means it missed none. Recall 0.5 means it missed half.
- Did it get the facts exact? For instance, are the prices read off exactly right, to the penny?
Put together, those give us the agent success rate for this job, which is the number that goes on the business map.
What we found in the first real run (our MVP):
+---------------------------------------------+ | RESULT (Uber Eats menu-QA, MVP run) | +---------------------------------------------+ | Reviewer: 3-model blinded ensemble | | (3 AI judges, scored separately,| | then compared) | | | | Seeded defects caught .... recall 1.0 | | (missed none) | | Prices read .............. exact | +---------------------------------------------+
A note on "3-model blinded ensemble": instead of trusting one AI judge, we run three different ones that cannot see each other's answers, then compare. If they agree, we are confident. If they disagree, that flags a hard spot worth a human look. On this task they agreed, caught every planted defect, and got the prices exact.
6. When do we build a SynthEnv, and when do we not?
This is the most important section. Building a practice arena is real work, so we only do it when we have to. The rule is simple.
Build a SynthEnv only when there is NO public website to test in.
If a public site already exists, just test there. Example: booking a flight. Skyscanner and the airline sites are public and free to use. The flights on offer change every time you look, but that is fine: our scoring judges cope with a different result on every run. No need to build anything.
Could you build a fixed Skyscanner clone to make a flight-booking test perfectly repeatable? Yes. But that is overkill for most attempts. Only do it when you specifically need a locked, repeatable benchmark with a frozen answer key.
Menu-extractor QA had no public reviewer screen with a fixed answer key, so building the SynthEnv was justified.
Here is the decision tree:
Is there a PUBLIC website
to test this task in?
|
+----------+----------+
| |
YES NO
| |
v v
Do you NEED a BUILD a SynthEnv
locked, repeatable (fixed data plus
answer key? a fixed answer key).
| e.g. the Uber Eats
+----+----+ menu-QA screen.
| |
NO YES
| |
v v
Just test Clean-room a
on the clone with
live site. set data to
e.g. book lock the test.
a flight (overkill for
on most cases.)
Skyscanner.
Read it top down: only the NO branch, or the rare "I need a locked benchmark" case, justifies the build. Everything else, use the live site.
7. The bottom line
The score from this arena, recall 1.0 on the seeded defects with prices exact, becomes ONE cell in the business automation map: menu-extractor QA, done well by an agent, today.
Honest note: this Uber Eats SynthEnv was an earlier, deliberately clean example, built about a month ago, to prove the approach works. The harder and more recent work is the automated improvement loop, where the system gets better at the task by itself. That is covered in a separate explainer: 03-iteration-machine-explainer.md.
The Iteration Machine: A Self-Improving Quality Loop
How a rough agent attempt gets scored, fixed, and re-scored until we have an honest success number to put on the map.
For: Rashid | Status: first-pass draft | Date: Tue 23 Jun 2026
1. What it is, in one sentence
The iteration machine is an automatic "write it, score it, fix the worst part, repeat" loop that takes a rough first draft of agent instructions and keeps improving it until it produces a measured, trustworthy success number.
This is the main event, and the newest work, because it is where the whole company idea gets put to the test by itself, with no human in the chair. The last 48 hours were spent building this loop and running it overnight.
A few terms, defined once:
- Laitent (also called aTTa or DKE): our company. The one-liner is "task mining for the agent era".
- Skill-SOP: the step-by-step instructions an AI agent runs for one task. Two layers. Tier-1 is the minimal steps to execute. Tier-2 is the why, the edge-cases, and the assumptions, read only when needed.
- Blinded Counsel (BC): a panel of independent AI judges that each score the work on their own, then we FLAG where they disagree. BC5 = 5 judges. Disagreement means low confidence, a "hard bit".
- KPI: a measured quality score. A gate is a KPI that MUST pass, or the whole thing fails.
2. Where this fits: the loop is the map's engine
What Laitent SELLS is not automations. It is a business-wide MAP of which work an AI agent can take over, and WHEN: now, or in +6, +12, or +18 months. We build that map by quietly watching an "automation guild" (a group of willing expert workers) and letting agents attempt their tasks. The proxy we use for "is this automatable?" is simple:
AGENT SUCCESS RATE. How often a fresh agent actually completes the task. That number, plus the honest confidence around it, is what fills one cell of the map.
The iteration machine is the engine that produces that number. For each captured task it drives a rough agent attempt up to a measured, trusted success level. That is the raw signal the map is built from.
ONE TASK THE ITERATION ONE CELL OF (from the guild) MACHINE THE MAP +-----------------+ +--------------+ +--------------+ | a captured | --> | drive a | --> | task X: | | expert task | | rough agent | | success 0.93 | | | | attempt up | | confidence: | | | | to a honest | | high | | | | success rate | | ready: now | +-----------------+ +--------------+ +--------------+ many tasks --> many honest cells --> the business map re-run as models improve --> the now / +6 / +12 / +18 roadmap
Two consequences flow from this, and the rest of the document is really about them:
- The number has to be HONEST, not flattering. An inflated success rate would tell a customer to fund the wrong roadmap. The executor gate (section 4) and the C0/C1/C2 test (section 5) exist to keep the number honest.
- The number has to be RE-RUNNABLE. We run the same task again as models get better; the success rate climbing over time is exactly what gives the now/+6/+12/+18-month projection.
3. The loop
One pass through the machine has four moves, then it repeats.
+---------------------------------------------------------+
| |
v |
+-----------+ +---------------+ +---------+ +---------+
| GENERATE |-->| EVALUATE |-->| ROUTE |-->| IMPROVE |
| / IMPROVE | | BC5 + rubric | | | | |
| | | 8 KPIs, | | a/b/c | | fix the |
| write the | | 4 hard GATES | | (below) | | single |
| two-tier | | | | | | worst |
| Skill-SOP | | keep any | | | | part |
| | | disagreement | | | | |
+-----------+ +---------------+ +---------+ +---------+
|
repeat until CONVERGED <------------------------+
(all gates pass, no hard failures,
no unresolved disagreement)
What each move does:
- GENERATE / IMPROVE. Write, or revise, the two-tier Skill-SOP for the captured task.
- EVALUATE. Score it with a BC5 (5 independent judges) against an 8-point quality rubric. Four of those 8 points are hard GATES that must pass. The crucial rule: if the judges DISAGREE, we KEEP the disagreement. We do not average it away. Averaging would let an over-confident "looks fine" quietly cancel out a "this is broken".
- ROUTE. Send each finding down one of three lanes (next).
- IMPROVE. Fix the SINGLE lowest-scoring part, then run again.
- STOP when CONVERGED (every gate passes, no hard failures, no unresolved disagreement), or when extra loops stop helping.
A word on the 8 KPIs, in plain terms. They check things like: is every step backed by what we actually recorded (not made up); could a fresh agent really run it; is the confidence honest; and is this one clean task rather than three jobs mixed together. The four that are GATES are the ones that, if failed, sink the whole SOP no matter how good the rest looks. You cannot buy your way past a gate with points elsewhere.
The three routing lanes
This is how the machine stays fast without a human babysitting it.
Finding from the judges
|
+-----------------+-----------------+
| | |
v v v
(a) AUTO- (b) DECIDE- (c) ESCALATE
SETTLE AND-LOG to Alex
(the default)
judges agree, an agent decides the rare genuine
close it. now; a human can authority call.
review it later.
keeps humans
UNblocked.
Lane (b), decide-and-log, is the default on purpose. Most calls are reversible, so an agent makes them now and logs them for later review. Only the rare call that genuinely needs the founder's authority goes to Alex. This is what lets the loop run all night unattended.
4. The key trick: judges vs doers
This is the headline. It is the founder's thesis, now measured. It is also the thing that makes a map cell honest instead of inflated.
The problem. A "lens-judge" is an AI judge that reads the WHOLE Skill-SOP, both tiers, and is asked "does this look runnable?" Judges like this OVER-score, because when they hit a gap they quietly fill it in their own heads, then mark the instructions as fine. A map built on that opinion would claim tasks are automatable when they are not.
The fix: the adversarial executor gate. Instead of asking a judge whether it LOOKS runnable, we hand a panel of FRESH agents ONLY the Tier-1 steps, with no extra context, and watch whether they can actually RUN it cold. Their honest success or failure is the real verdict for "can an agent execute this?" That single KPI is called K2, agent-executability, and it is the one that feeds the success rate on the map.
THE JUDGE (over-scores) THE DOER (honest)
reads BOTH tiers, fills gets Tier-1 ONLY, no
any gap in its own head context, tries to RUN it
+-------------------+ +-------------------+
| "Step 1 is vague, | | Step 1: "open the |
| but I know what | | app." ...which |
| they mean." | | app? No name. I |
| | | am stuck. |
| Verdict: FINE | | |
+-------------------+ | Verdict: FAILED |
+-------------------+
looks runnable, actually hit the wall.
gap papered over. the wall is the truth.
What happened when we measured it. The lens-judges marked all 3 Skill-SOPs as fine. The fresh executors then REFUTED two of the three: handed only Tier-1, they could not run them. (SOP-1 and SOP-2 each got a unanimous "non-executable" from three doers; SOP-3 was confirmed runnable.) The DISAGREEMENT between "looks fine" and "actually ran" was the entire signal. So the rule was hardened: K2 now REQUIRES passing the fresh-executor panel, not just judge opinion.
The one-line moral: honest execution beats confident opinion; disagreement is the signal. That is the company thesis, proven in miniature, and it is precisely why a Laitent map can be trusted enough to fund a roadmap against it.
5. How we measure real value: the C0 / C1 / C2 test
The executor gate answers "can an agent run the steps at all?" The C0/C1/C2 test answers a richer question the map needs: "how much does the captured know-how actually HELP, and how much of the value is the unwritten reasoning?" We give the same task to fresh agents under three conditions and compare their scores.
C0 C1 C2 no SOP steps only full SOP (wing it) (the WHAT) (WHAT + WHY) score score score +----+ +------+ +----------+ | | | | | | | | | | | | +----+ +------+ +----------+ low higher highest SOP lift = C1 - C0 (how much the steps alone help) WHY gap = C2 - C1 (how much the tacit reasoning adds)
- C0 = no SOP at all. The agent just wings it.
- C1 = the SOP's WHAT: the steps only.
- C2 = the full SOP: the steps PLUS the why.
Two useful numbers fall out:
- SOP lift = C1 minus C0 = how much the bare steps help.
- WHY gap = C2 minus C1 = how much the unwritten reasoning adds on top.
Worked example: the Uber Eats menu-QA task. It scored C1 = 0.59, then C2 = 0.93, a WHY gap of +0.46. (Scores run 0 to 1.) Meaning: the tacit judgment was worth a LOT. For the map, that is a double finding. The task IS automatable to a high level, but only once the expert's reasoning is captured. A big WHY gap is a flag that this cell needs a human-interview step before an agent can hit the top number.
This test also caught two traps. Both matter because either one would quietly corrupt a map cell:
- Scenario-leak. If the practice scenario accidentally reveals the answer, the no-SOP agent already "knows", so C0 is falsely high and the WHY gap collapses to look like zero. The map would then wrongly say "no expert knowledge needed here". Fix: the scenario PLANTS the traps but never resolves them; the answers live only in a hidden rubric.
- Verify-by-execution beats scoring a described plan. One task scored 0.83 when we judged its written plan, but only 0.40 when the agent actually RAN it (it made real mistakes a plan-read missed). A map built on plan-reading would be off by that whole gap. Always test by doing, not by reading the plan.
6. Two laws the loop discovered
- The self-containment law. A Skill-SOP is truly runnable only if its Tier-1 is self-contained. Every blank to fill in (every "<param>") needs a line telling the agent where to get it ("bind <param> from <source> before step 1"); all needed content must be reachable; and anything that cannot be resolved is explicitly fenced OUT of the "done" definition. The tension: making instructions general (good for reuse) WITHOUT saying where to get the inputs BREAKS runnability. A mature SOP needs BOTH the blank AND the line that says how to fill it.
- The why is capturable to the degree the artifact IS the reasoning. Tasks whose output literally IS the thinking (writing a spec, authoring a rule) give up their why easily. Tasks that just decide-and-act (buy this, send that) hide their why and are harder to capture. This is a targeting rule: it tells us which cells of the map we can fill cheaply now, and which need a human-interview layer.
7. Where it stands, and the tie-back
Overnight, the loop ran 4 times and CONVERGED: all 3 Skill-SOPs reached reviewed-eligible.
One honest point. "Reviewed-eligible" is NOT the same as "certified". Certification is the one call reserved for the founder, Alex, backed by hard evidence. So the machine gets the work to the doorstep of trust, and a human still signs off.
rough draft --> [ loop x4 ] --> reviewed-eligible --> Alex
(machine stops here) |
v
certified
(human signs off)
The tie-back, in one breath. Laitent sells a trustworthy map of what is automatable and when. A map is only as good as the numbers in its cells. The iteration machine is what produces those numbers: it drives each captured task up to a measured success rate, and the executor gate plus the C0/C1/C2 test are how that number stays HONEST instead of inflated. Re-running the same loop as the models improve is what turns a snapshot into the now/+6/+12/+18-month roadmap. The loop is small; what it protects, the credibility of the whole product, is not.